Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment. Data ingestion is important in any big data project because the volume of data is generally in petabytes or exabytes.
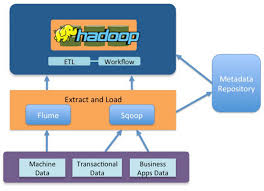
Hadoop Sqoop and Hadoop Flume are the two tools in Hadoop which is used to gather data from different sources and load them into HDFS. Sqoop in Hadoop is mostly used to extract structured data from databases like Teradata, Oracle, etc., and Flume in Hadoop is used to sources data which is stored in various sources like and deals mostly with unstructured data.
If you would like more information about Big Data careers, please click the orange “Request Info” button on top of this page.
Big data systems are popular for processing huge amounts of unstructured data from multiple data sources. The complexity of the big data system increases with each data source. Most of the business domains have different data types like marketing genes in healthcare, audio and video systems, telecom CDR, and social media. All these have diverse data sources and data from these sources is consistently produced on large scale. Get more skills from ETL Testing Course
The challenge is to leverage the resources available and manage the consistency of data. Data ingestion is complex in hadoop because processing is done in batch, stream or in real time which increases the management and complexity of data. Some of the common challenges with data ingestion in Hadoop are parallel processing, data quality, machine data on a higher scale of several gigabytes per minute, multiple source ingestion, real-time ingestion and scalability.
Apache Sqoop and Apache Flume are two popular open source etl tools for hadoop that help organizations overcome the challenges encountered in data ingestion. If you are looking to find the answer to the question –“What’s the difference between Flume and Sqoop?” then you are on the right page.
The major difference between Sqoop and Flume is that Sqoop is used for loading data from relational databases into HDFS while Flume is used to capture a stream of moving data.
What is Sqoop in Hadoop?
Apache Sqoop (SQL-to-Hadoop) is a lifesaver for anyone who is experiencing difficulties in moving data from the data warehouse into the Hadoop environment. Apache Sqoop is an effective hadoop tool used for importing data from RDBMS’s like MySQL, Oracle, etc. into HBase, Hive or HDFS. Sqoop hadoop can also be used for exporting data from HDFS into RDBMS. Apache Sqoop is a command line interpreter i.e. the Sqoop commands are executed one at a time by the interpreter.
Need for Apache Sqoop
With increasing number of business organizations adopting Hadoop to analyse huge amounts of structured or unstructured data, there is a need for them to transfer petabytes or exabytes of data between their existing relational databases, data sources, data warehouses and the Hadoop environment. Accessing huge amounts of unstructured data directly from MapReduce applications running on large Hadoop clusters or loading it from production systems is a complex task because data transfer using scripts is often not effective and time consuming.
How Apache Sqoop works?
Sqoop is an effective hadoop tool for non-programmers which functions by looking at the databases that need to be imported and choosing a relevant import function for the source data. Once the input is recognized by Sqoop hadoop, the metadata for the table is read and a class definition is created for the input requirements. Hadoop Sqoop can be forced to function selectively by just getting the columns needed before input instead of importing the entire input and looking for the data in it.
This saves considerable amount of time. In reality, the import from the database to HDFS is accomplished by a MapReduce job that is created in the background by Apache Sqoop. For more info ETL Testing Training
Features of Apache Sqoop
- Apache Sqoop supports bulk import i.e. it can import the complete database or individual tables into HDFS. The files will be stored in the HDFS file system and the data in built-in directories.
- Sqoop parallelizes data transfer for optimal system utilization and fast performance.
- Apache Sqoop provides direct input i.e. it can map relational databases and import directly into HBase and Hive.
- Sqoop makes data analysis efficient.
- Sqoop helps in mitigating the excessive loads to external systems.
- Sqoop provides data interaction programmatically by generating Java classes.
What is Flume in Hadoop?
Apache Flume is service designed for streaming logs into Hadoop environment. Flume is a distributed and reliable service for collecting and aggregating huge amounts of log data. With a simple and easy to use architecture based on streaming data flows, it also has tunable reliability mechanisms and several recovery and failover mechanisms.
Need for Flume
Logs are usually a source of stress and argument in most of the big data companies. Logs are one of the most painful resources to manage for the operations team as they take up huge amount of space. Logs are rarely present at places on the disk where someone in the company can make effective use of them or hadoop developers can access them. Many big data companies wind up building tools and processes to collect logs from application servers, transfer them to some repository so that they can control the lifecycle without consuming unnecessary disk space.
This frustrates developers as the logs are often not present at the location where they can view them easily, they have limited number of tools available for processing logs and have confined capabilities in intelligently managing the lifecycle. Apache Flume is designed to address the difficulties of both operations group and developers by providing them an easy to use tool that can push logs from bunch of applications servers to various repositories via a highly configurable agent.
How Apache Flume works?
Flume has a simple event driven pipeline architecture with 3 important roles-Source, Channel and Sink.
- Source defines where the data is coming from, for instance a message queue or a file.
- Sinks defined the destination of the data pipelined from various sources.
- Channels are pipes which establish connect between sources and sinks.
Apache flume works on two important concepts-
- The master acts like a reliable configuration service which is used by nodes for retrieving their configuration.
- If the configuration for a particular node changes on the master then it will dynamically be updated by the master.
Node is generally an event pipe in Hadoop Flume which reads from the source and writes to the Sink. The characteristics and role of a flume node is determine by the behaviour of source and sinks. Apache Flume is built with several source and sink options but if none of them fits in your requirements then developers can write their own. A flume node can also be configured with the help of a sink decorator which can interpret the event and transforms it as it passes through. With all these basic primitives, developers can create different topologies to collect data on any application server and direct it to any log repository.
To get in-depth knowledge, enroll for a live free demo on ETL Testing Online Training
