Well here it is a year later, and it looks like ADP has done it. The company’s next-generation HCM and payroll system is now available, and could become one of the more disruptive systems on the market. While the system is still young, it sets a technical direction for Workday, SAP, Oracle, and others.
How The HR Software Market Has Changed
Let me briefly discuss how the HR software market has changed. Core Human Capital systems are a large, growing and important market. Once considered the “system of record” for employees, they are now used by every company as a way to keep track of people’s jobs and work, plan and facilitate careers, and make sure people are paid correctly.
Now, they are changing again.
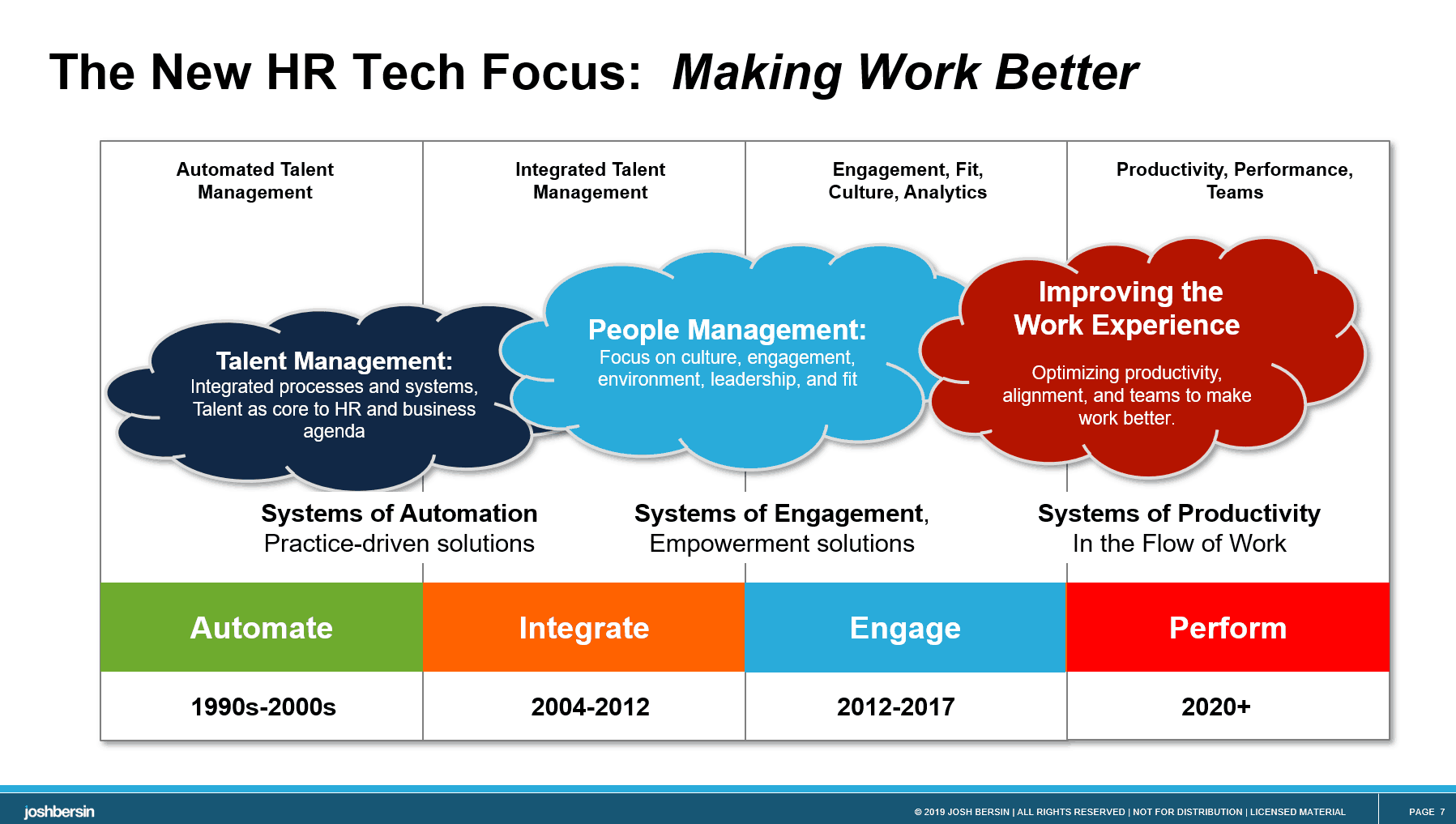 |
Today’s HCM platforms are no longer just systems of record, they are systems to make employees’ work lives better. They have to support many organization models (hierarchy, teams, projects, contractors, gig workers); they have to address many forms of reward and pay (salary, hourly, by the project, by output); and they have to be open to many third-party applications. For more info Workday training
Organizations now function as talent networks, not hierarchies. 34% of companies tell us they operate as a network (up from 6% in 2016), and more than 88% of companies tell me they want a better technology to manage gig and contract work. Zappos, Schneider Electric, Unilever and many others now manage themselves as “talent marketplaces,” encouraging people to play roles in multiple teams around the world.
And these new HCM platforms are not just “applications,” but rather micro-services platforms where applications run. Some of the most innovative apps in HR now come from third parties. HCM vendors simply cannot build everything themselves. I now think of core HCM as “application ecosystems,” more like the i-Phone than like Quickbooks.
Moreover, these systems have be designed around “experiences” not “processes.” The word Experience is now the biggest buzzword in HR, and it is profoundly changing the way software is developed. It’s no longer sufficient to build forms, tabs, and buttons for users: now we have to build systems that adapt to our needs, listen to our voice, change based on our data, and can be configured in many ways.
(Both SuccessFactors and Workday are just launching Experience Layers on top of their systems to address this.)
Finally, the HCM system of the future has to be an employee productivity tool, not jus an HR tool. It isn’t designed for HR anymore, it must be designed for employees and managers. The system should be useful, simple to use, and must interface with Microsoft Teams, Slack, WhatsApp, and all the other various collaboration tools we use at work.
In short, this is a whole new world – and it requires a new architecture, new user experience, and new technology stack.
ADP, An Unexpected Tech Leader
This industry is not for the faint of heart. Building an enterprise platform takes years, and once you start you’re stuck with the architecture you start with.
Workday’s architecture is fourteen years old and quite innovative, it feels proprietary. SuccessFactors is similar in age and is now being re-engineered around SAP Hana and a new Experience interface. Oracle recently re-engineered its HCM platform and it took almost five years. So when a company like ADP starts from scratch, it can upset the apple cart.
While many customers rushed to buy cloud-based HCM systems, their satisfaction has been mixed. The platforms are highly complex, they don’t accommodate new organization and performance models, and buyers want more innovation. HR departments want a stable, reliable HCM platform but they also want to be able to mix and match the best of breed on top.
Today, using what is called “cloud-native” systems, vendors can build modern applications faster than ever. And technologies like AI, cognitive interfaces, natural language processing, and graph database are readily available from Amazon Web Services, Google Cloud, or Microsoft.
Enter ADP.
ADP you say? Aren’t they a 70-year-old payroll company? What are they doing in the cloud architecture business?
Well yes, ADP does pay more than 40 million people in the US (one in six). But behind the scenes, the company is filled with technologists, and its new Lifion group has assembled some of the most senior tech architects in the world.
As Carlos Rodriguez the CEO and Don Weinstein the head of Global Product and Technology put it, ADP used to be a “services company fueled by technology.” Now it is becoming “a technology company with great services.” In other words, the company has heavily invested in its platform.
The new platform, today called ADP Next Gen HCM (a real name will come), has the architecture other vendors only talk about, and as it picks up speed it could become a major disruptor in the market.
What Is ADP Next Gen HCM?
Let me explain what ADP has done.
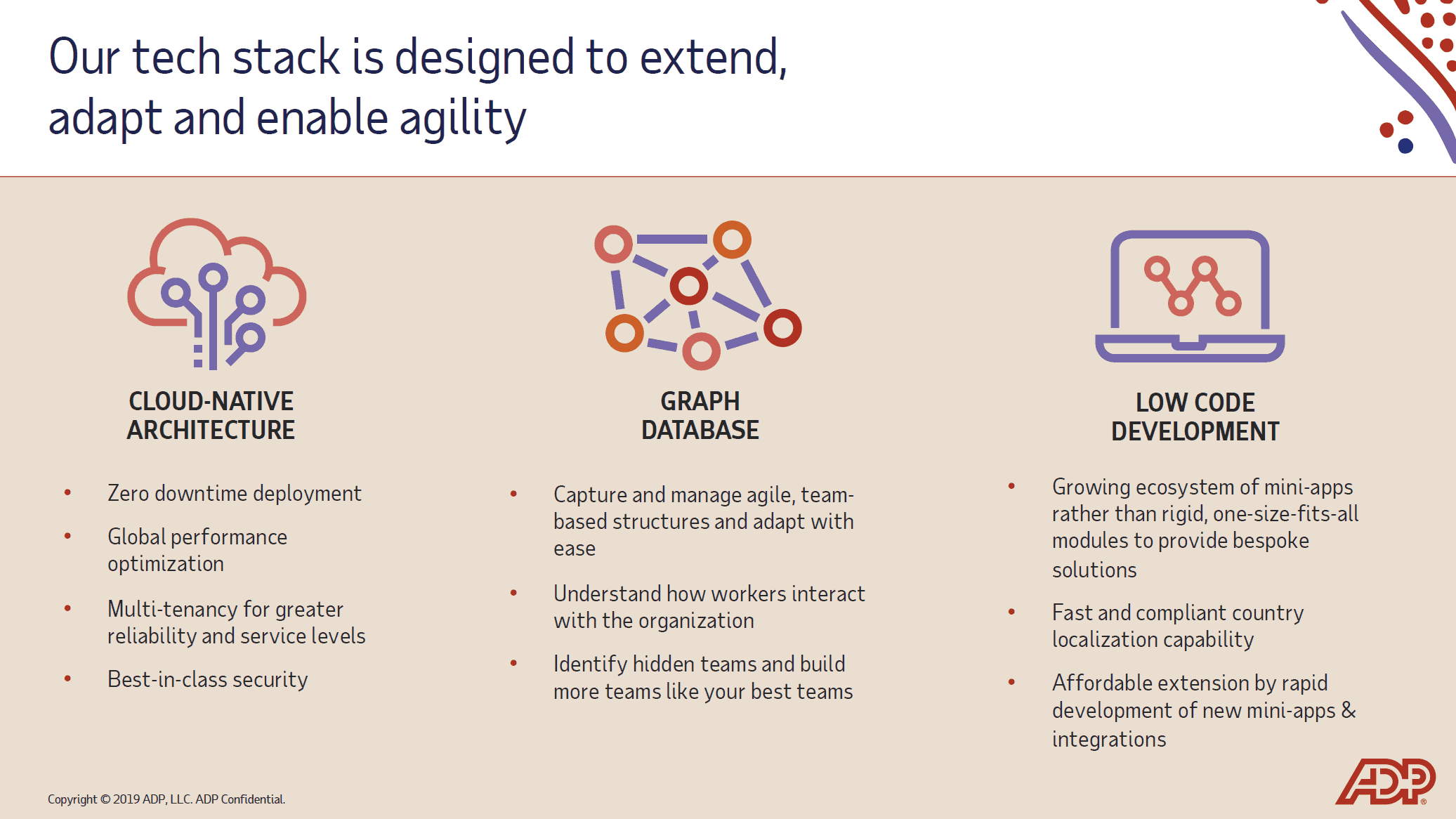
Through a skunk-works development team in Chelsea, NY, the company has been rewriting its payroll engine and HCM platform for several years. The project, originally called Lifion, is a “cloud-native” platform which embraces the latest technology stack needed to scale for the future.
“Cloud-native” simply means it’s built on the newest, containerized services, leveraging the latest technology in the cloud. This means the system is made up of many micro-apps, it uses low-code development, it leverages graph and SQL databases, and it never goes down for maintenance.
 |
Let me give you some specifics.
- ADP’s new architecture is designed around teams, not hierarchies, so it has capabilities to manage the future of work. You can create teams of any type in the system, and then include any type of worker in a team (full time, part-time, contingent). Teams inherit the hierarchical attributes of people (ie. who they report to) but also attribute them to the team. (Imagine a project team working on a new product, a safety team, and even an employee resource group.)
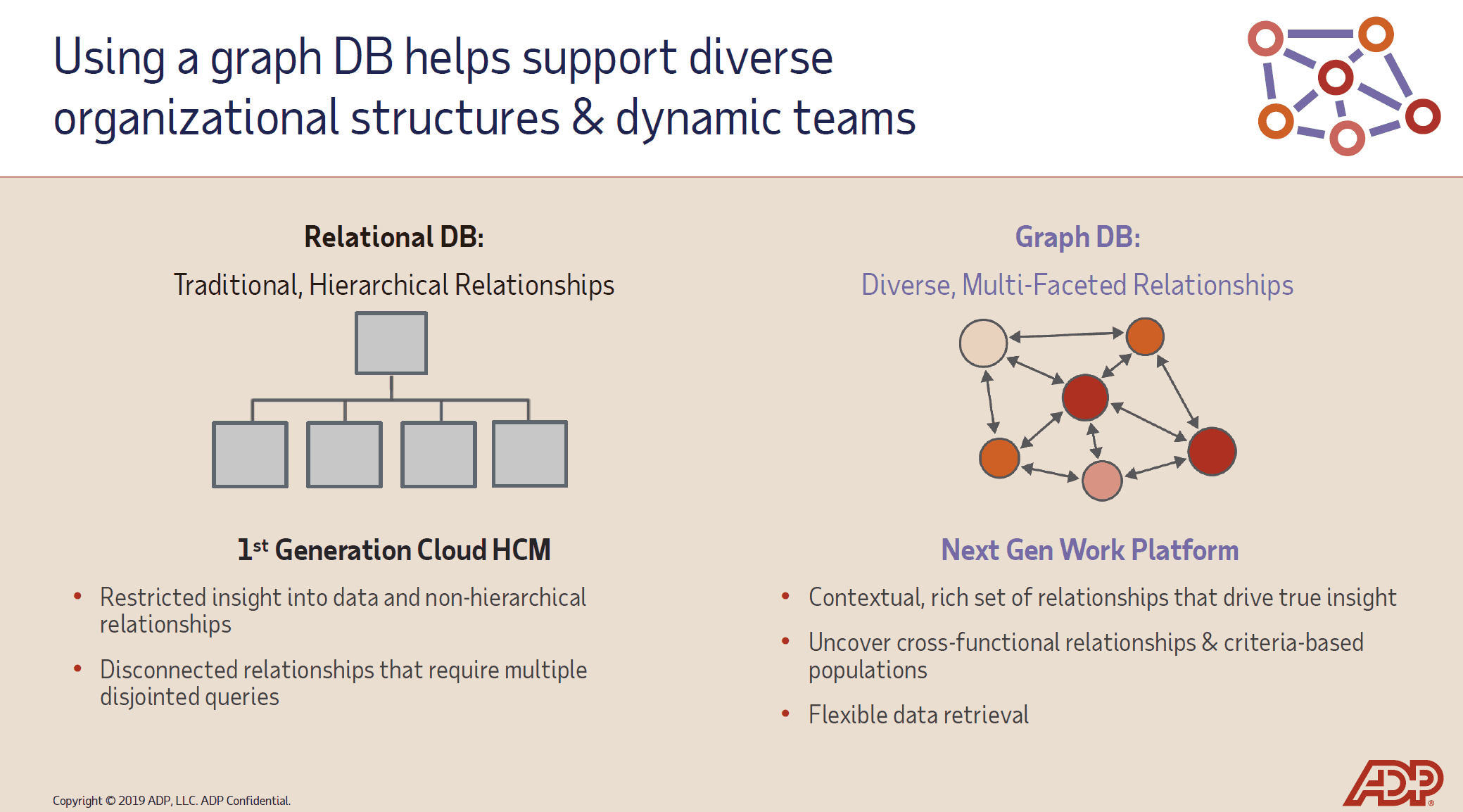
- Unlike other HCM systems, each Team is an entity in itself, with its own business rules, apps, and measurement systems. You could have one team that uses an OKR goal application, another that uses a different survey tool. Teams are essentially the “grain” of the architecture, not the hierarchy. This is only possible because the system uses a Graph Database. Graph database technology models data as relationships, not rows and columns. (It’s the tech under Facebook and Google.) It has immense potential in organizations today.
- The system is designed for “micro-apps and micro-services.” This means ADP can quickly build new applications easily, plug third party applications into the system, and open up the system for users and consultants to build apps. Think of the ADP Platform as a giant i-Phone: you can plug in any app and inherit all the data and security you’ve already built. You can assign apps to teams, so some teams can use one type of goal setting, another can use other features, and so on.
- The development environment is “low-code,” meaning you can build apps in a visual tool. This means ADP and partners can extend the system easily, creating a flexible non-proprietary model to grow and expand.

- ADP’s system is mobile-first and visually simple. The system uses a consumer-like interface (similar to Google), and seems very easy to use. Workday, which originally built a very innovative user interface, is feeling its age, and plans a major upgrade this Fall. SuccessFactors new HXM interface (Human Experience Management) is also a major push in this direction.
- ADP’s AI engine is useful out of the box. And that’s not just because it uses AI, it’s because ADP has so much data. ADP houses more data about workers and jobs than any other company in the world, so if you want to know if your people are underpaid or if your retention is out of line, ADP has benchmarks you can use. The AI-based intelligence application delivers suggestions and recommendations on hundreds of talent issues, all in a “narrative intelligence” interface.

- Just to let you know how much data the company has, ADP has more than 800,000 customers and a skills-cloud with more than 30 million employees’ job descriptions embedded.

- ADP’s talent applications are also coming along. Clients sometimes complain about various parts of ADP’s recruitment or learning software, but StandOut, ADP’s next-generation engagement, goal, performance management, and team coaching system is a very competitive product. It is integrated into Next Gen HCM so it can be deployed immediately to any or all teams. The product has been highly successful in ADP, driving a 6% improvement in engagement and a 12% increase in sales productivity. 97% of ADP associates have completed the StandOut assessment, an aspiration most companies would dream of. (Cisco is also a big fan.)

- ADP’s Next Gen Payroll engine, coupled with the company’s acquisition of Celegro, uses a reusable rules engine to greatly reduce the complexity of payroll. Payroll is a complex business operation filled with lots of special rules. The Next Gen payroll system is designed to be “rules driven.” Microsoft uses ADP’s Global Payroll and has reduced the number of global payroll administrators from 400 to a handful of payroll SMEs across the globe.
- ADP’s new payment system is redesigned for real-time pay (the payroll engine computes all gross-to-net and deductions in real-time). This lets companies pay employees and contractors more frequently.
- ADP’s Wisely system, the company’s smart payment app, is gaining more than 250,000 new members per month, making it one of the fastest-growing payment systems in the market. (Wisely lets you allocate pay to different categories, automatically create various forms of savings accounts, and use credit/debit and other pay methods right from your payroll.)
To get in-depth knowledge, enroll for a live free demo on Workday Online Training










{kind=link}